Flink——从零搭建Flink应用
主要内容:
- 环境准备
- 创建Flink项目模板
- 编写Flink程序
- 运行测试
环境准备
Flink执行环境分为本地环境和集群环境,可运行在Linux、Windows和Mac OS上。首先介绍环境依赖:
JDK:版本要求:1.8及以上Maven:Flink源码目前仅支持通过Maven进行编译,版本要求:3.0.4及以上Scala:根据开发语言选择是否安装(本教程使用Scala开发,高效简洁)Hadoop:根据部署方式选择是否安装(若使用On Yarn模式需要安装)
Java环境:
$ java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
Maven环境:
$ mvn -version
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: D:\Program\ideaMaven\apache-maven-3.6.3
Java version: 1.8.0_241, vendor: Oracle Corporation, runtime: D:\Program\Java\jdk1.8.0_241\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
Flink开发环境:推荐使用IntelliJ IDEA:ideaIU-2019.3.4。安装及破解方式请参考:这里!这里!
创建Flink项目模板
使用Flink Maven Archrtype来创建Maven项目。方法及相关信息:
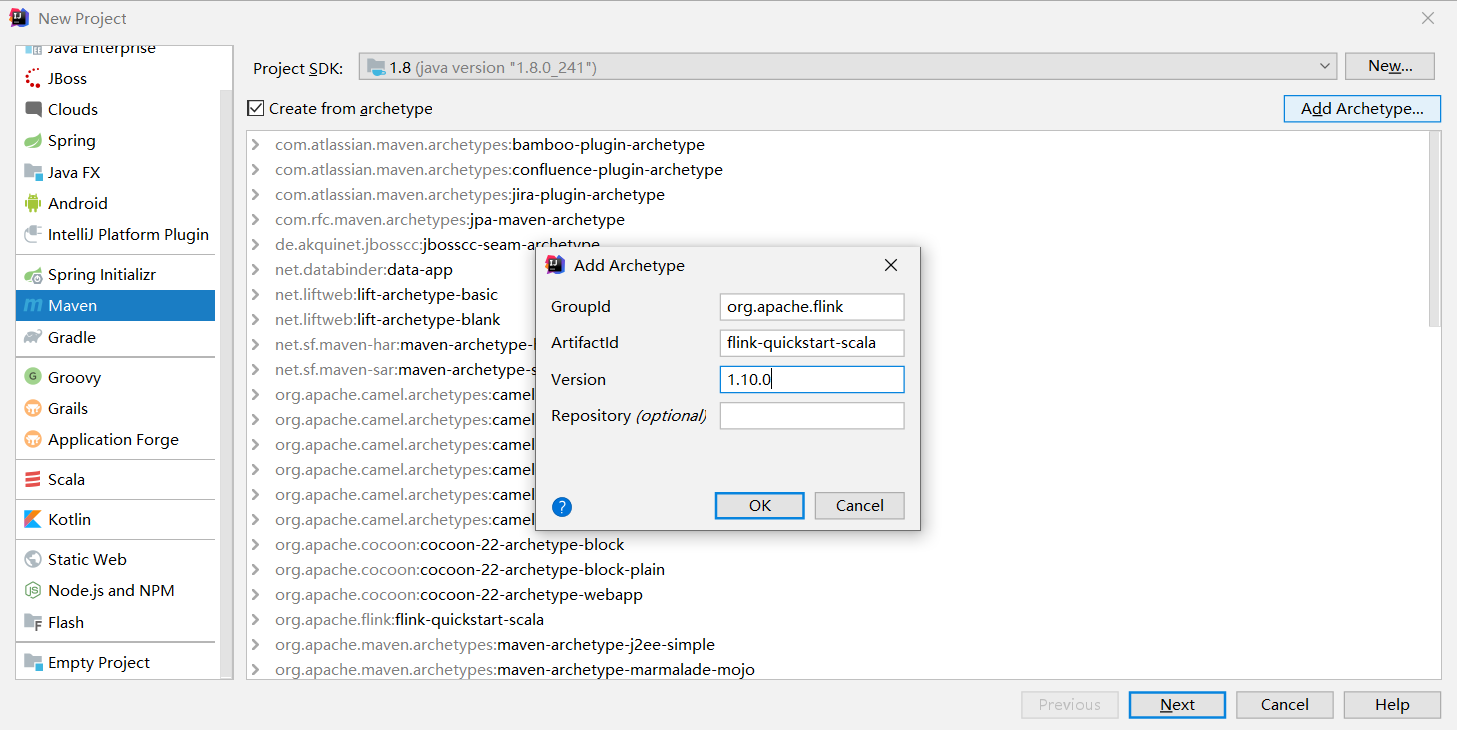
或者命令行:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.10.0
创建好的原始项目结构:
flink-dev
├── pom.xml
└── src
└── main
├── scala
│ └── org.ourhome
│ ├── BatchJob.scala # 批处理程序
│ └── StreamingJob.scala # 流处理程序
└── resources
└── log4j.properties
目录升级:创建了一个 config.properties 文件来配置项目的常用配置数据;创建一个 env 子目录,并创建两个环境对应的配置文件,不同的环境当中使用不同的配置:config.test.properties:测试环境,config.prod.properties:开发环境。升级后的目录结构:
# resoures 目录
.
├── env
│ ├── config.test.properties
│ └── config.prod.properties
└── config.properties
编写Flink程序
Flink程序结构:

-
设置执行环境:这是一个入口类,可以用来设置参数和创建数据源以及提交任务。
StreamExecutionEnvironment:流处理环境ExecutionEnvironment:批处理环境
-
初始化数据:将数据引入Flink,
ExecutionEnvironment提供多种接口完成数据初始化,可将外部数据装换成DataStream<T>或DataSet<T>。同时Flink也提供了多种从外部读取数据的连接器,包括批量和实时的数据连接器,能够将Flink和第三方系统连接,直接获取外部数据,如Kafka。 -
执行转换操作:转换操作都是通过Operator来实现,每个Operator内部通过实现Function接口完成数据处理逻辑的定义,如map、filter、keyBy、flatMap等。用户只需要定义每种算子执行的函数逻辑,然后在数据转换操作Operator接口中即可。
-
指定计算结果数据位置:数据集经过转换操作之后,形成最终的结果数据集,可存储到外部系统。Flink的DataStream和DataSet接口中定义了基本的数据输出方法:
writeAsText()基于文件输出,print()基于控制台输出。同时Flink也定义了大量连接器,通过调用addSink(),可方便用户和外部系统交互。 -
命名并启动任务:通过调用
execute()触发应用程序的执行。对于流式程序的开发,需要显式调用execute()方法运行程序,而批处理程序中已包含对execute()方法的调用。
下面是完整的代码:
package org.ourhome
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
val params: ParameterTool = ParameterTool.fromArgs(args)
val host: String = params.get("host")
val port: Int = params.getInt("port")
// 1 set env
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2 add data
val socketData: DataStream[String] = env.socketTextStream(host, port)
// 3 transformation
val wordCountData = socketData.flatMap(_.toLowerCase.split(" "))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
// 4 add sink or print
wordCountData.print()
// 5 name flink job and trigger task
env.execute("wordcount")
}
}
运行测试
提交程序时需要传入两个参数:host和port:
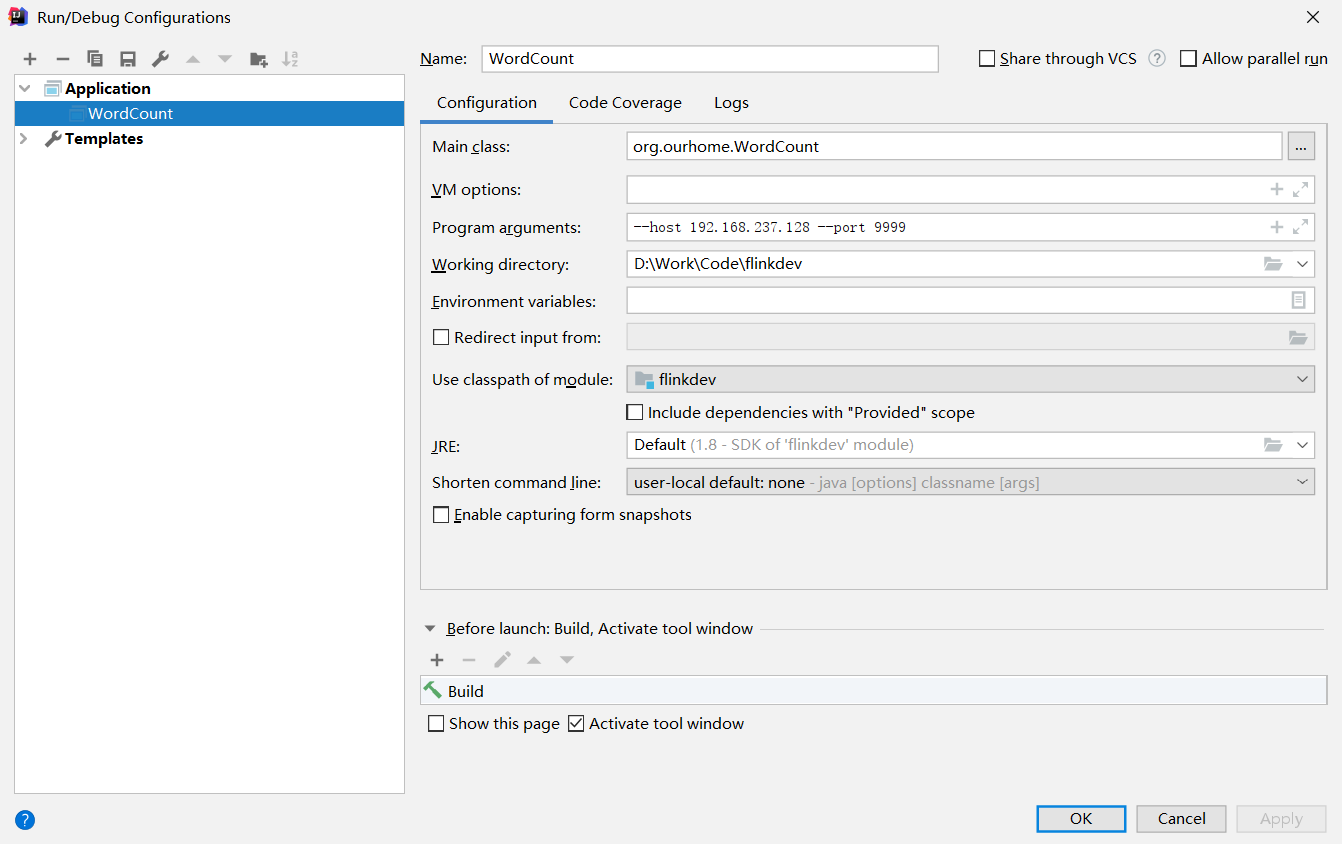
结果:
(hello,1)
(scala,1)
(hello,2)
(flink,1)
(flink,2)
(scala,2)
初次使用Flink请注意
-
对于使用项目模板生成的项目,项目中的主要参数已被初始化,多以无需额外进行配置,如果用户通过手工进行项目的创建,则需要创建Flink项目并进行相应的基础配置,包括:Maven依赖、Scala版本等配置信息。
-
Flink两大依赖:
- 核心依赖:Flink本身由一组类(DataStream/DataSet API)和运行时需要的依赖构成。当一个Flink程序启动时,Flink核心的这些类和依赖在运行时必须存在;
- 应用依赖:所有的连接器、formats或者类库等用户程序需要的东西。应用程序一般都打包成一个jar包,它包含应用程序代码以及所需要的连接器和库的依赖关系。Flink应用依赖明确不包含DataStream/DataSet API和运行时依赖,因为这些已经包含在Flink的核心依赖了。
基于scala开发Flink,核心依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> <scope>provided</scope> </dependency>请注意:核心依赖配置的
scope为provided,意味着:编译时需要,而打包时不打进去。因为这些依赖时Flink的核心依赖,当启动Flink集群的时候它们已经存在。若没有该参数,轻则会造成所打包过大,重则造成类冲突(因应用程序添加的依赖和集群的依赖版本不同而冲突)。**但是,本地运行时要将该参数改为compile!!!**否则报错——踩坑之经验!连接器(如Kafka)不是Flink的核心依赖,在运行时必须添加依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.10_2.11</artifactId> <version>1.4.1</version> </dependency> -
Scala版本:Scala版本(2.10、2.11、2.12等)不是相互兼容的,出于这个原因,flink
scala2.11不能适用于使用scala2.12的应用程序。所有的flink依赖项取决于对应的scala后缀,这个表示使用对应的scala版本进行编译的。例如:flink-streaming-scala_2.11表示使用scala2.11版本进行编译的。