Flume——简介及原理
主要内容:
- 简介
- 优势
- 组成
- 事务性
- Flume Agent内部原理
- Flume配置文件配置流程
简介
Apache Flume是一个分布式、高可用、高可靠的系统,可以有效地从许多不同的源收集、聚合和移动海量日志数据到集中式数据存储。
Flume可用于传输大量事件数据:
- 日志数据
- 网络流量数据
- 社交媒体数据
- 电子邮件消息
- ……
优势
- 支持将数据存储到任何集中存储器中,比如HDFS,Hive,HBase;
- 当传入数据的速率超过可以将数据写入目标的速率时,flume充当数据生产者和集中存储之间的中介,并在它们之间提供稳定的数据流;
- channel是基于事务,保证了数据在传送和接收时的一致性;
- 可靠的,容错性高的,可扩展的,易管理的,并且可定制的;
- 支持各种接入数据的类型以及接出数据类型;
- 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等;
- 支持水平扩展。
组成
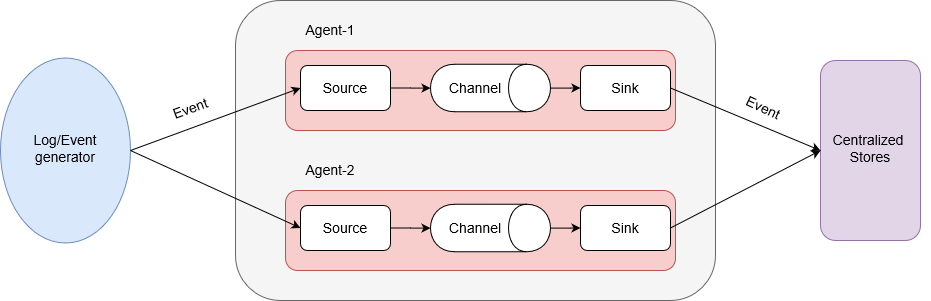
agent:agent是一个JVM进程,它以事件的形式将数据从源头送至目的地。由三个部分组成:- source
- channel
- sink
event:数据传输的基本单元,带有一个可选的消息头。如果是文本文件,通常是一行记录;event从source,流向channel,再到sink;source:负责接收数据到agent的组件,支持处理各种类型、各种格式的日志数据;channel:主要提供一个队列的功能,是位于source和sink之间的缓冲区。自带两种channel:Memory Channel:基于内存缓存,在不需要关心数据丢失的情境下适用;File Channel:Flume的持久化channel。在程序关闭或机器宕机的情况下不会丢失数据。
sink:sink不断地轮询channel中的事件且批量地移除它们。并将这些事件批量写入到存储或索引系统、或者被发送到另一个flume agent。
Flume事务
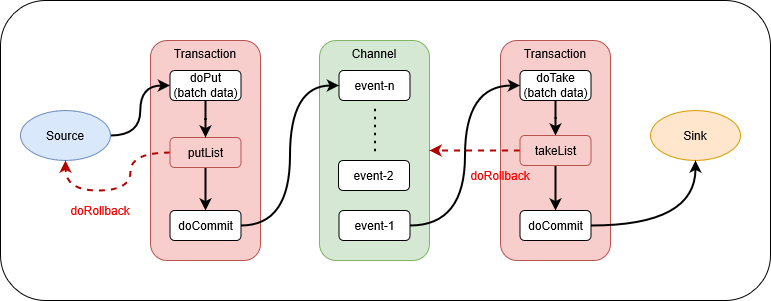
Flume的事务性主要体现在两个方面:
put事务:从source到channel的事件传输过程叫Put事务。通过doPut将批数据先写入临时缓冲区putList;再通过doCommit将批数据提交给channel。一旦事务中的所有事件全部传递到channel且提交成功,那么source就将其标记为完成。如果因为某种原因事件传递失败,那么事务将会回滚。take事务:从channel拉取事件数据到sink的过程叫take事务。通过doTake先将数据取到临时缓冲区takeList;再通过doCommit将事件数据发送到sink。如果数据全部发送数据成功,则清除临时缓冲区takeList。如果数据发送过程中出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存序列。
Flume Agent内部原理
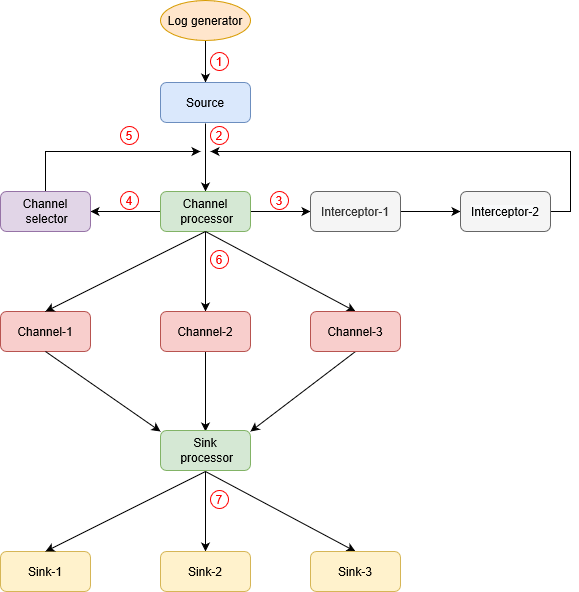
Flume agent内部工作流程:
- Source采集数据;
- 在Source内部,由
EventBuilder.withBody(body)将数据封装成event对象,由source.getChannelProcessor().processEvent(event)将交给Channel处理器; - Channel 处理器将event传给Interceptor拦截器链,进行简单的数据清洗过滤,然后将其返回给Channel 处理器;
- Channel 处理器再将过滤之后的event传给Channel选择器,Channel选择器决定每个event写入哪个Channel,以及哪些Channel时必需的或可选的。Channel选择器分两种:
Replicating Channel Selector:默认,将source过来的event发往所有的channel(相当于复制多份);Multiplexing Channel Selector:可以配置source发过来的event具体发往哪些Channel。其工作原理就是根据event的header中的key-value来判断该event该发往哪一个Channel。而event中的header是拦截器过滤好event之后给event加的具体的header,即key-value。所以,一般都是拦截器和Multiplexing Channel Selector结合起来使用。
- Channel选择器返回event的channel列表;
- 根据Channel选择器的选择结果,将event写入相应的channel;
- Sink 处理器选择其中一个sink去获取channel中的event,并将获取的event写入下一个阶段。通过配置Sink groups,可以实现sink的负载均衡和故障转移。其中:Sink processor有三种:
DefaultSinkProcessor:默认的,内部无任何逻辑,只是单纯的调用sink;LoadBalancingSinkProcessor:负载均衡;FaioverSinkProcessor:容灾恢复。
Flume配置文件配置流程
Flume配置文件是具有键值对的Java属性文件,配置分为5步:
- Name the components of the current agent.
- Describe/Configure the source.
- Describe/Configure the sink.
- Describe/Configure the channel.
- Bind the source and the sink to the channel.
Flume支持多种Source、Channel和Sink:
Source:
Avro SourceThrift SourceExec SourceJMS SourceSpooling Directory SourceTwitter 1% firehose SourceKafka SourceNetCat SourceSequence Generator SourceSyslog SourcesSyslog TCP SourceMultiport Syslog TCP SourceSyslog UDP SourceHTTP SourceStress SourceLegacy SourcesThrift Legacy SourceCustom SourceScribe Source
Channel:
Memory ChannelJDBC ChannelKafka ChannelFile ChannelSpillable Memory ChannelPseudo Transaction Channel
Sink:
HDFS SinkHive SinkLogger SinkAvro SinkThrift SinkIRC SinkFile Roll SinkNull SinkHBaseSinkAsyncHBaseSinkMorphlineSolrSinkElasticSearchSinkKite Dataset SinkKafka Sink