Hadoop分布式文件系统
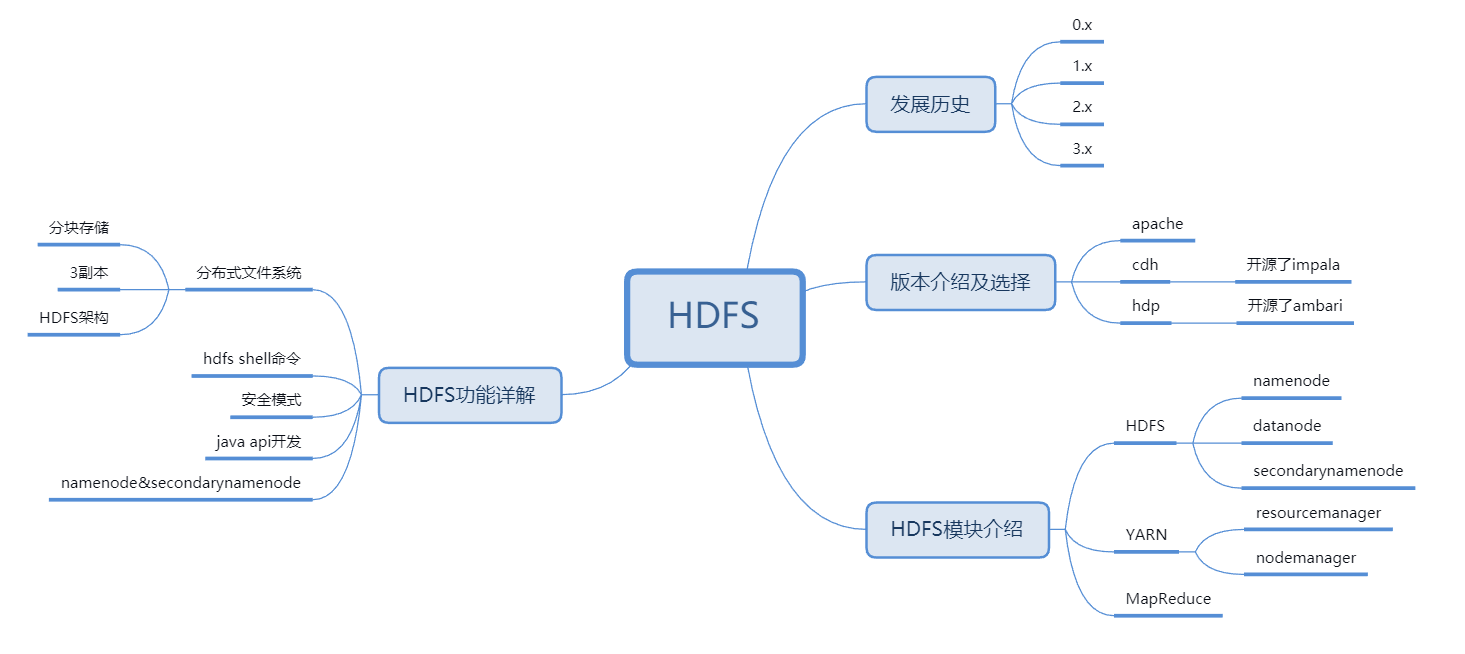
目标
- 理解分布式文件系统
- 理解hdfs架构
- 熟练hdfs基本命令使用
- 掌握hdfs编程
- 理解namenode及secondarynamenode交互
Hadoop的发展历史起源
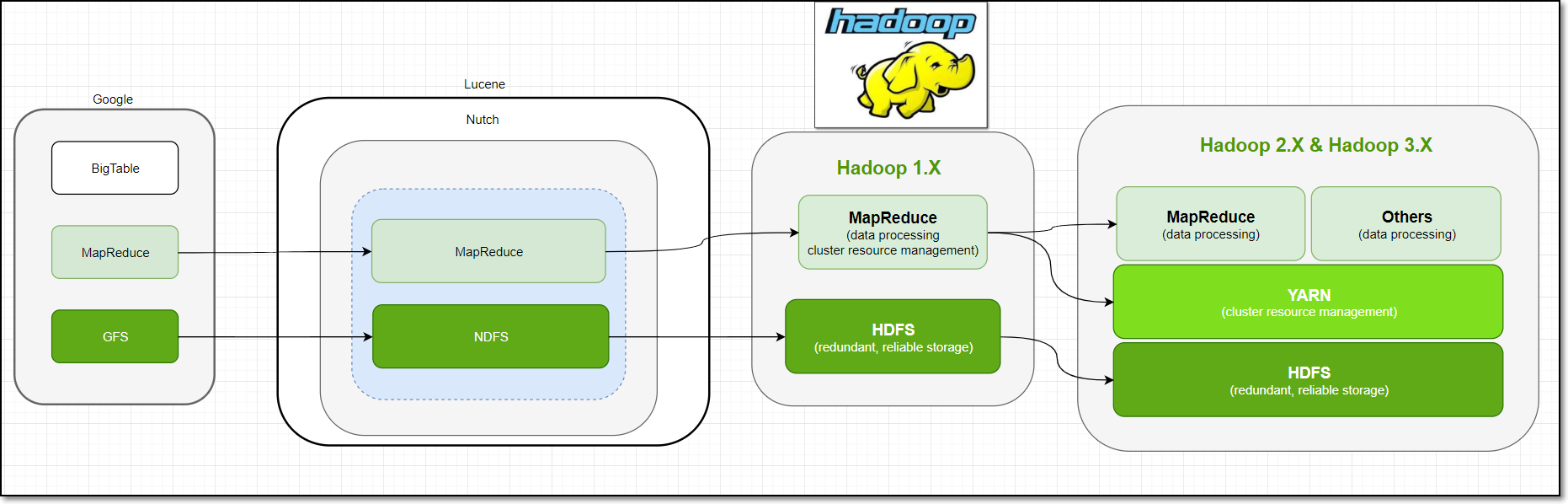
hadoop理解:
- 狭义上来说,hadoop就是单独指代hadoop这个软件
- 广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件

hadoop的发展版本:
-
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本。
-
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等。
-
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,也是现在生产环境当中使用最多的版本。
-
3.x版本系列:在2.x的基础上,引入了一些hdfs的新特性等,且已经发型了稳定版本,未来公司的使用趋势。
hadoop生产环境版本选择:
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
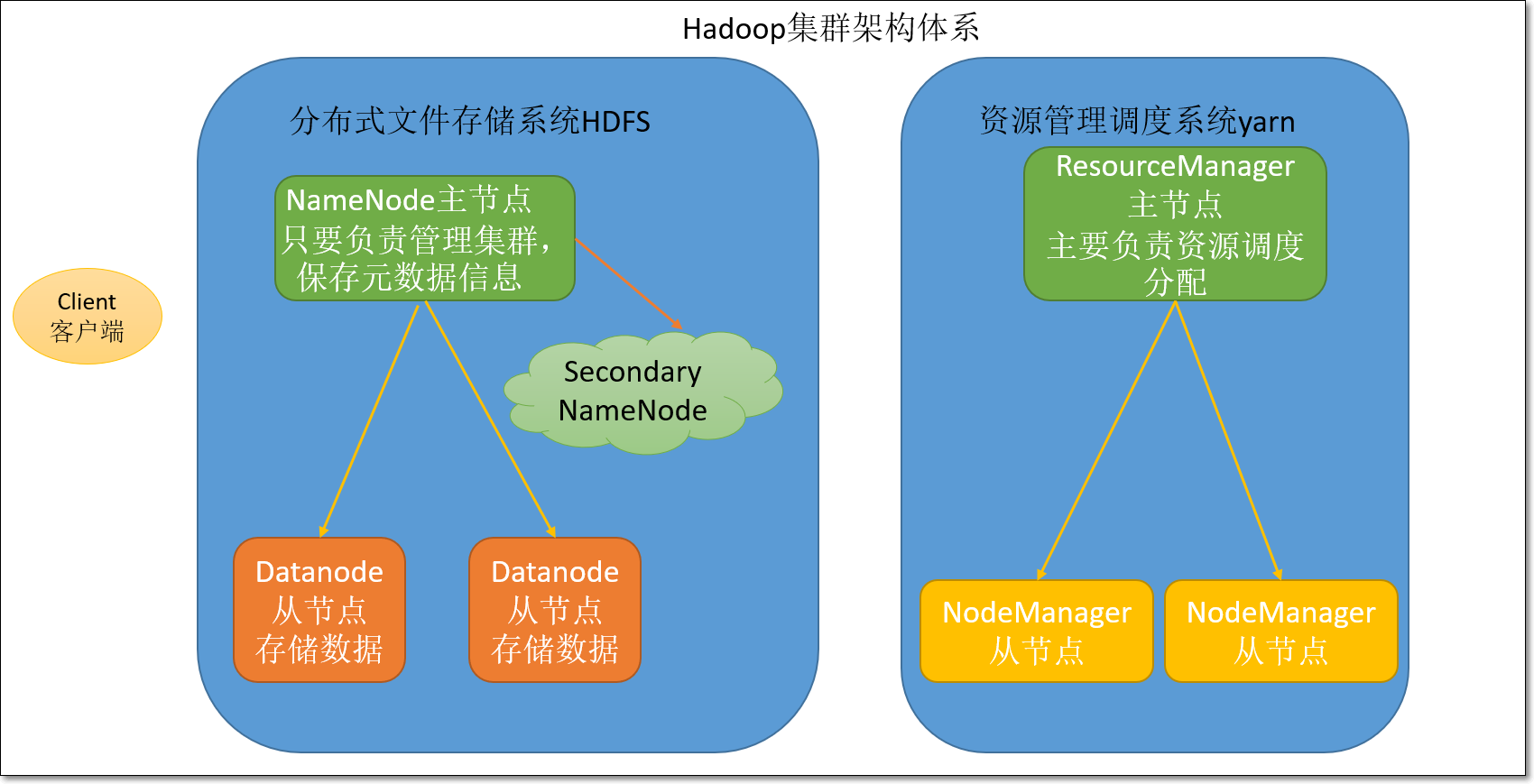
hadoop的架构模块介绍:

Hadoop由三个模块组成:分布式存储HDFS、分布式计算MapReduce、资源调度引擎Yarn。
-
HDFS模块:
-
namenode:主节点,主要负责集群的管理以及元数据信息管理。
-
datanode:从节点,主要负责存储用户数据。
-
secondaryNameNode:辅助namenode管理元数据信息,以及元数据信息的冷备份。
-
-
Yarn模块:
- ResourceManager:主节点,主要负责资源分配。
- NodeManager:从节点,主要负责执行任务。
hdfs功能详解介绍
最直观的理解便是三个臭皮匠,顶个诸葛亮。
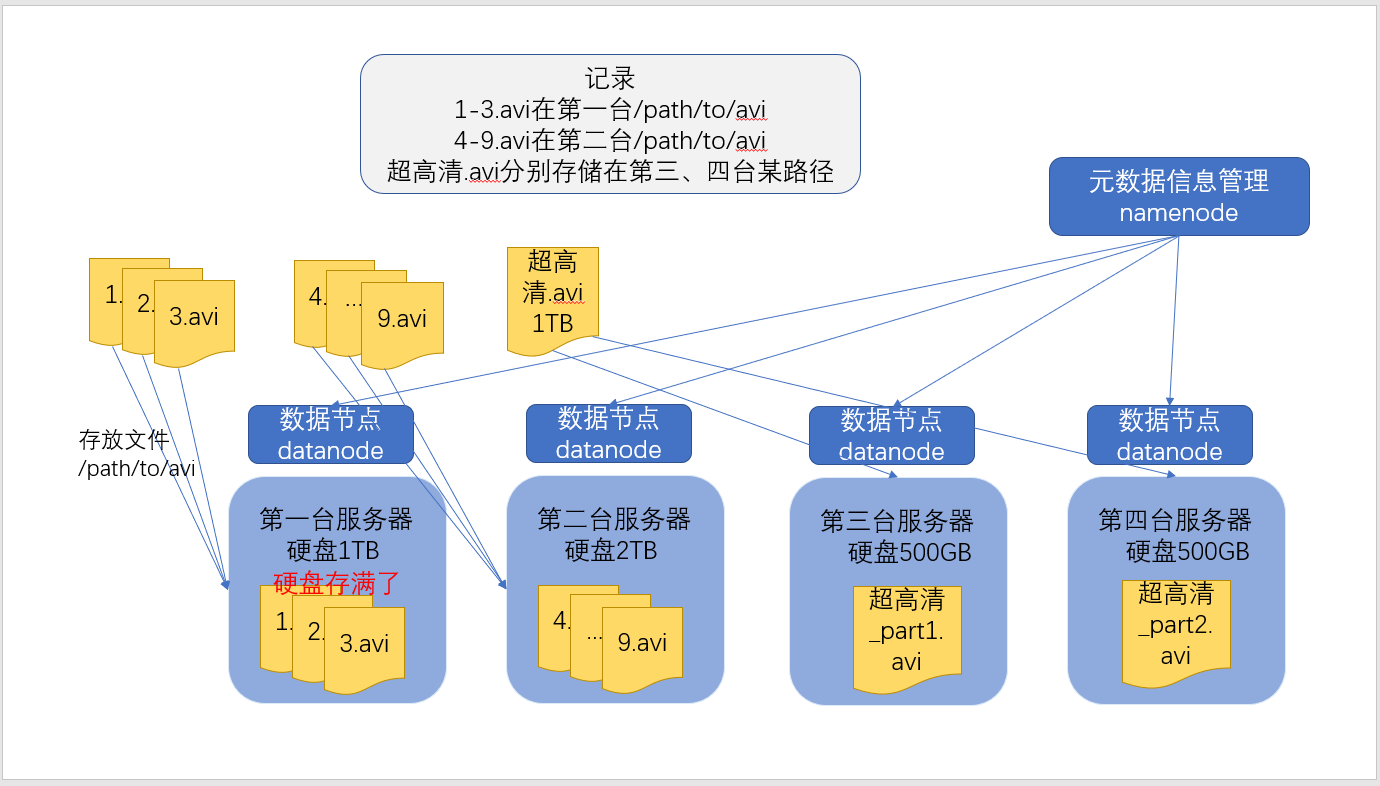
文件分块存储&3副本:
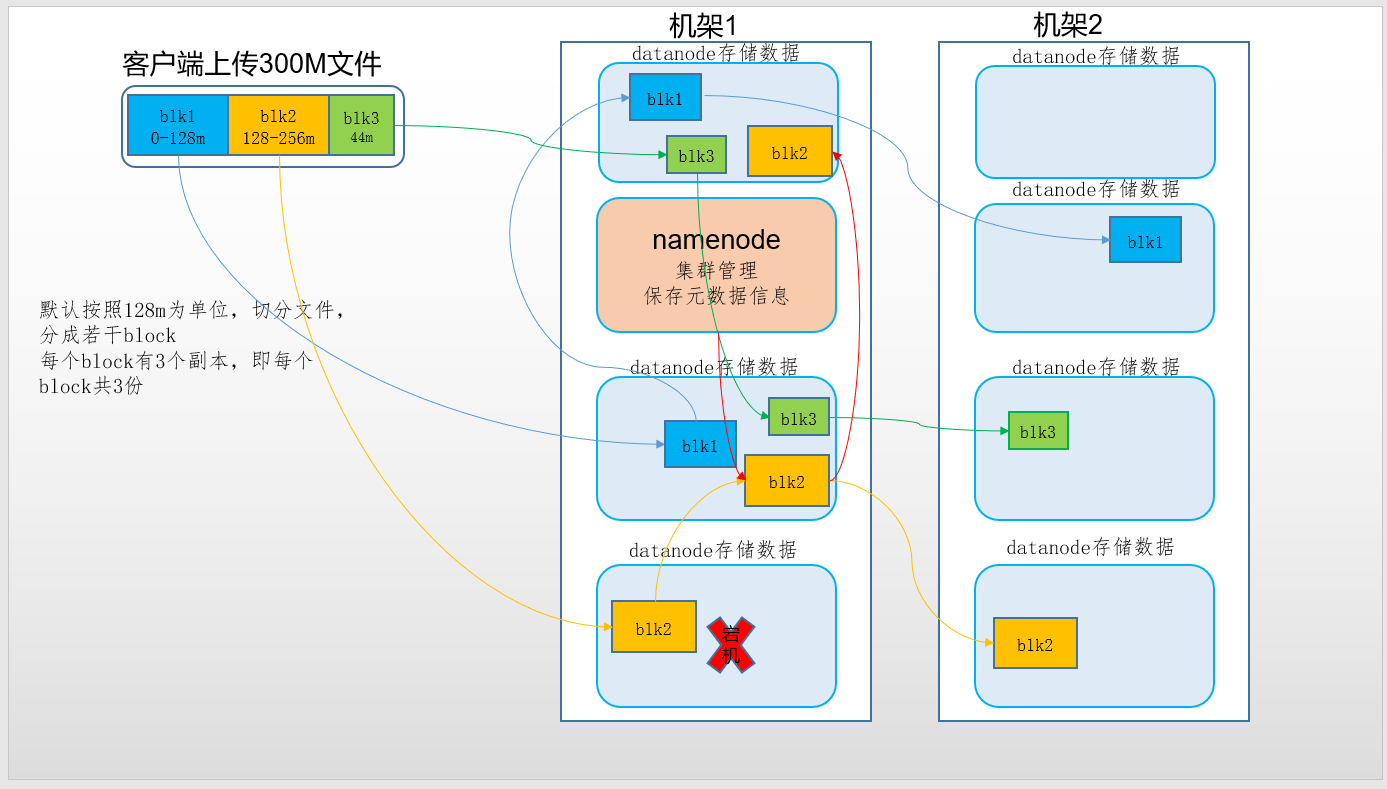
- 保存文件到HDFS时,会先默认按128M的大小对文件进行切分,效果如上图。
- 数据以block块的形式进统一存储管理,每个block块默认最多可以存储128M的文件。
- 如果有一个文件大小为1KB,也是要占用一个block块,但是实际占用磁盘空间还是1KB大小,类似于有一个水桶可以装128斤的水,但是我只装了1斤的水,那么我的水桶里面水的重量就是1斤,而不是128斤。
- 每个block块的元数据大小大概为150字节。
- 所有的文件都是以block块的方式存放在HDFS文件系统当中,在hadoop1当中,文件的block块默认大小是64M;hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定:
<property>
<name>dfs.block.size</name>
<value>块大小 以字节为单位</value><!-- 只写数值就可以 -->
</property>
- 为了保证block块的安全性,也就是数据的安全性,在hadoop2当中,文件默认保存三个副本,我们可以更改副本数以提高数据的安全性。
- 在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
抽象成数据块的好处:
-
一个文件有可能大于集群中任意一个磁盘 :
10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件。 -
使用块抽象而不是文件可以简化存储子系统:
hdfs将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的形式进行存储,方便我们的分布式文件系统对文件的管理。
-
块非常适合用于数据备份进而提供数据容错能力和可用性。
HDFS架构:
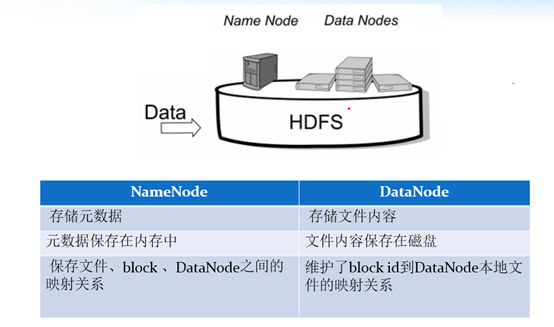
HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
- NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
- DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
- Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息。
NameNode与Datanode的总结概述:
hdfs的shell命令操作:
HDFS命令有两种风格:
- hadoop fs开头的
- hdfs dfs开头的
- 两种命令均可使用,效果相同
- 如何查看hdfs或hadoop子命令的帮助信息,如ls子命令
hdfs dfs -help ls
hadoop fs -help ls #两个命令等价
- 查看hdfs文件系统中指定目录的文件列表。对比linux命令ls
hdfs dfs -ls /
hadoop fs -ls /
hdfs dfs -ls -R /
- 在hdfs文件系统中创建文件
hdfs dfs -touchz /edits.txt
- 向HDFS文件中追加内容
hadoop fs -appendToFile edit1.xml /edits.txt #将本地磁盘当前目录的edit1.xml内容追加到HDFS根目录 的edits.txt文件
- 查看HDFS文件内容
hdfs dfs -cat /edits.txt
- 从本地路径上传文件至HDFS
#用法:hdfs dfs -put /本地路径 /hdfs路径
hdfs dfs -put /linux本地磁盘文件 /hdfs路径文件
hdfs dfs -copyFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样
hdfs dfs -moveFromLocal /linux本地磁盘文件 /hdfs路径文件 #跟put作用一样,只不过,源文件被拷贝成功后,会被删除
- 在hdfs文件系统中下载文件
hdfs dfs -get /hdfs路径 /本地路径
hdfs dfs -copyToLocal /hdfs路径 /本地路径 #根get作用一样
- 在hdfs文件系统中创建目录
hdfs dfs -mkdir /shell
- 在hdfs文件系统中删除文件
hdfs dfs -rm /edits.txt
- 在hdfs文件系统中修改文件名称(也可以用来移动文件到目录)
hdfs dfs -mv /xcall.sh /call.sh
hdfs dfs -mv /call.sh /shell
- 在hdfs中拷贝文件到目录
hdfs dfs -cp /xrsync.sh /shell
- 递归删除目录
hdfs dfs -rm -r /shell
- 列出本地文件的内容(默认是hdfs文件系统)
hdfs dfs -ls file:///home/hadoop/
- 查找文件
# linux find命令
find . -name 'edit*'
# HDFS find命令
hadoop fs -find / -name part-r-00000 # 在HDFS根目录中,查找part-r-00000文件
- 总结
-
输入hadoop fs 或hdfs dfs,回车,查看所有的HDFS命令
-
许多命令与linux命令有很大的相似性,学会举一反三
-
有用的help,如查看ls命令的使用说明:hadoop fs -help ls
-
绝大多数的大数据框架的命令,也有类似的help信息
hdfs安全模式:
- 安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),hdfs集群刚启动的时候,默认30S钟的时间是出于安全期的,只有过了30S之后,集群脱离了安全期,然后才可以对集群进行操作
- 何时推出安全模式
- namenode知道集群共多少个block(不考虑副本),假设值是total;
- namenode启动后,会上报block report,namenode开始累加统计满足最小副本数(默认1)的block个数,假设是num
- 当num/total > 99.9%时,推出安全模式。
[hadoop@node01 hadoop]$ hdfs dfsadmin -safemode
Usage: hdfs dfsadmin [-safemode enter | leave | get | wait]
NameNode和SecondaryNameNode功能剖析:
1.namenode与secondaryName解析:
-
NameNode主要负责集群当中的元数据信息管理,而且元数据信息需要经常随机访问,因为元数据信息必须高效的检索,那么如何保证namenode快速检索呢??元数据信息保存在哪里能够快速检索呢??如何保证元数据的持久安全呢??
-
为了保证元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中元数据信息能够最快速的检索,那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。
-
如果所有的元数据信息都存放内存,服务器断电,内存当中所有数据都消失,为了保证元数据的安全持久,元数据信息必须做可靠的持久化,在hadoop当中为了持久化存储元数据信息,将所有的元数据信息保存在了FSImage文件当中,那么FSImage随着时间推移,必然越来越膨胀,FSImage的操作变得越来越难,为了解决元数据信息的增删改,hadoop当中还引入了元数据操作日志edits文件,edits文件记录了客户端操作元数据的信息,随着时间的推移,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNamenode来专门做fsimage与edits文件的合并。
namenode工作机制:
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志。
(4)namenode在内存中对数据进行增删改查
Secondary NameNode工作机制:
(1)Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage
2.FSImage与edits详解:
- 所有的元数据信息都保存在了FsImage与Eidts文件当中,这两个文件就记录了所有的数据的元数据信息,元数据信息的保存目录配置在了hdfs-site.xml当中:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
</property>
-
客户端对hdfs进行写文件时会首先被记录在edits文件中。
edits修改时元数据也会更新。
每次hdfs更新时edits先更新后客户端才会看到最新信息。
fsimage:是namenode中关于元数据的镜像,一般称为检查点。
一般开始时对namenode的操作都放在edits中,为什么不放在fsimage中呢?
因为fsimage是namenode的完整的镜像,内容很大,如果每次都加载到内存的话生成树状拓扑结构,这是非常耗内存和CPU。
fsimage内容包含了namenode管理下的所有datanode中文件及文件block及block所在的datanode的元数据信息。随着edits内容增大,就需要在一定时间点和fsimage合并。
3. FSimage文件当中的文件信息查看
-
官方查看文档
-
使用命令 hdfs oiv
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000864 -p XML -o hello.xml
4. edits当中的文件信息查看
-
官方查看文档
-
查看命令 hdfs oev
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
hdfs oev -i edits_0000000000000000865-0000000000000000866 -o myedit.xml -p XML
5. secondarynameNode如何辅助管理FSImage与Edits文件
6. namenode元数据信息多目录配置
-
为了保证元数据的安全性,我们一般都是先确定好我们的磁盘挂载目录,将元数据的磁盘做RAID1
namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
-
具体配置如下:
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>