Spark——JoinSelection策略
主要内容:
- 介绍Join的三种实现方式
- 介绍Spark中的Join策略

在数据分析领域,Join操作是非常常见的数据处理操作。Spark作为一个统一的大数据处理引擎,提供了丰富的Join场景。
1、Join的实现方式
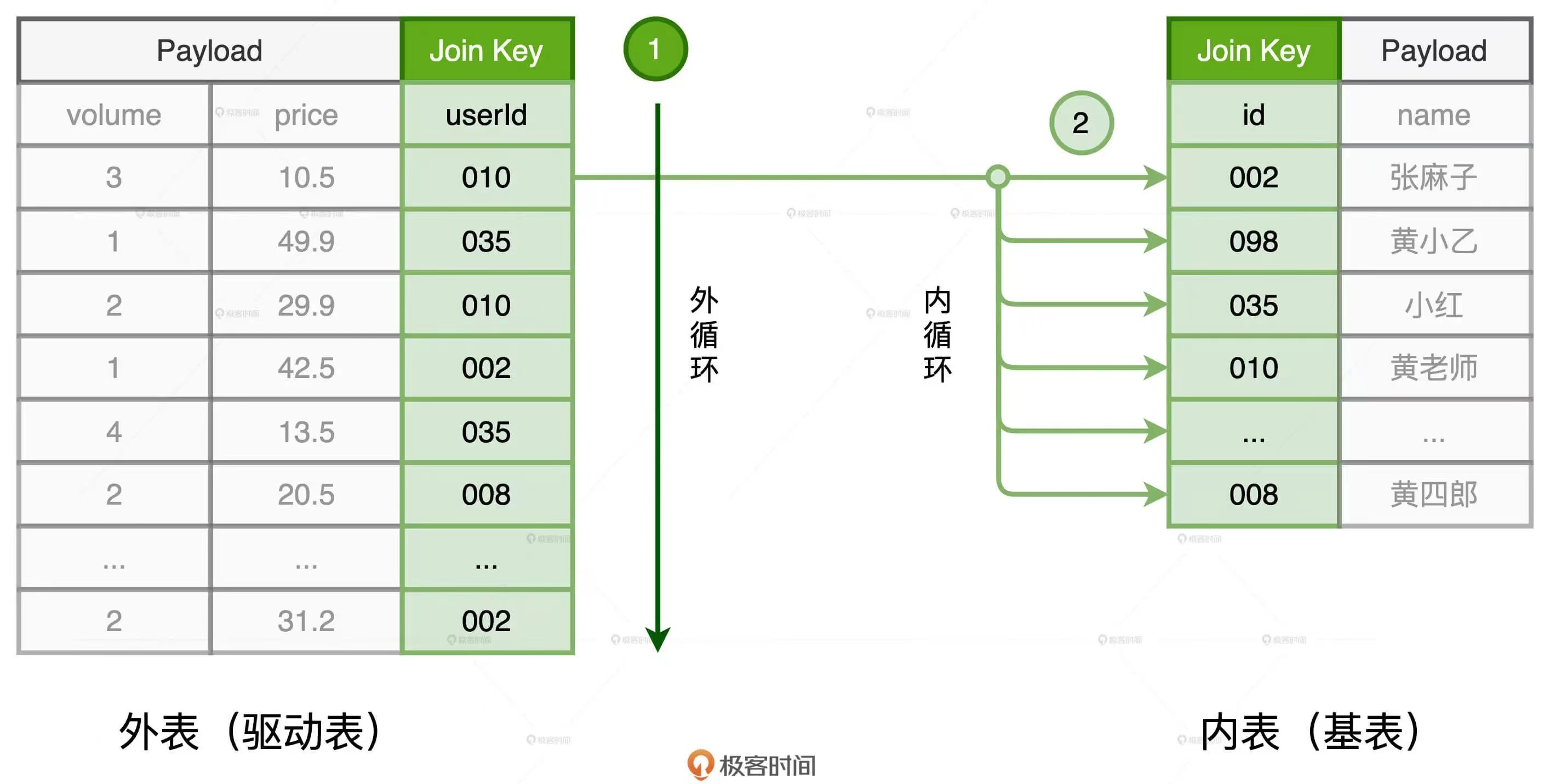
循环嵌套-Nested Loop Join(NLJ):对于关联的两张表,大表作为外表或者驱动表;小表作为内表或者基表。NLJ是采用“循环嵌套”的方式实现关联。使用两个嵌套的for循环扫描数据,判断关联条件是否满足。外层for循环负责遍历外表中的每一条数据,内层for循环负责遍历内表中的每一条数据,即外表中的一条数据,就会遍历内表中的所有记录。假设外表有M行,内表有N行,那么NLJ算法的时间复杂度是O(M*N)。
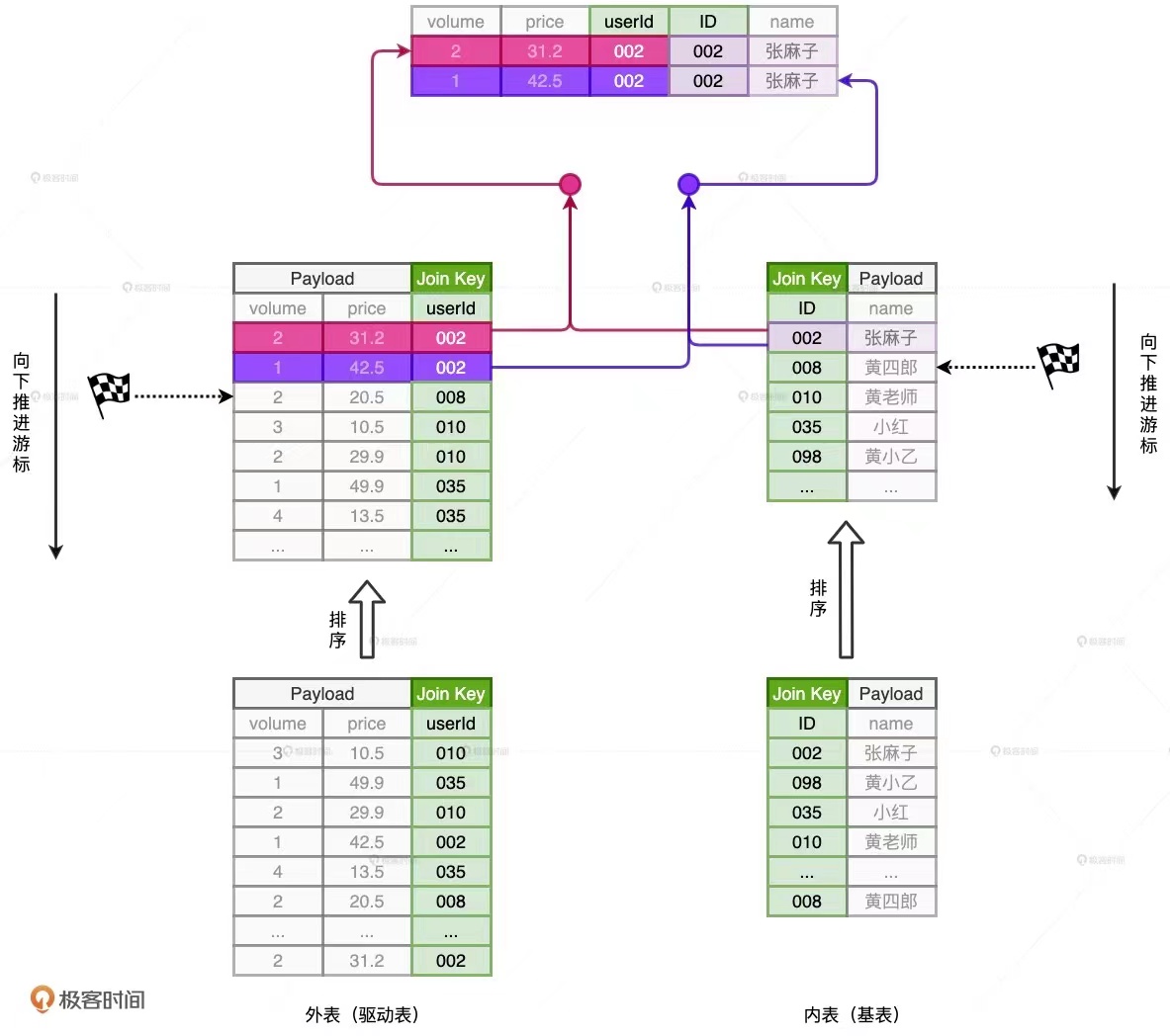
排序归并-Sort Merge Join(SMJ):SMJ的思路是先排序,后归并。具体来说,就是参与Join的两张表先分别按照Join Key进行排序,然后使用两个独立的游标对排好序的两张表完成归并关联。开始时,内外表的游标都会先指向各自表的第一行记录,然后对比游标所在记录的Join Key。对比结果以及后续操作主要分为三种情况:
- 外表 Join Key 等于内表 Join Key,满足关联条件,把两边的数据记录拼接并输出,然后把外表的游标滑动到下一条记录
- 外表 Join Key 小于内表 Join Key,不满足关联条件,把外表的游标滑动到下一条记录
- 外表 Join Key 大于内表 Join Key,不满足关联条件,把内表的游标滑动到下一条记录
SMJ对排序的要求比较苛刻。其能具有线性的时间复杂度,仰仗的是两张表已经事先排好序。而排序在大数据领域本身就是一项非常耗时的操作。由于SMJ中内表按Join Key升序排序,且扫描的起始位置为游标所在位置,因此,SMJ算法的时间复杂度是O(M+N)。
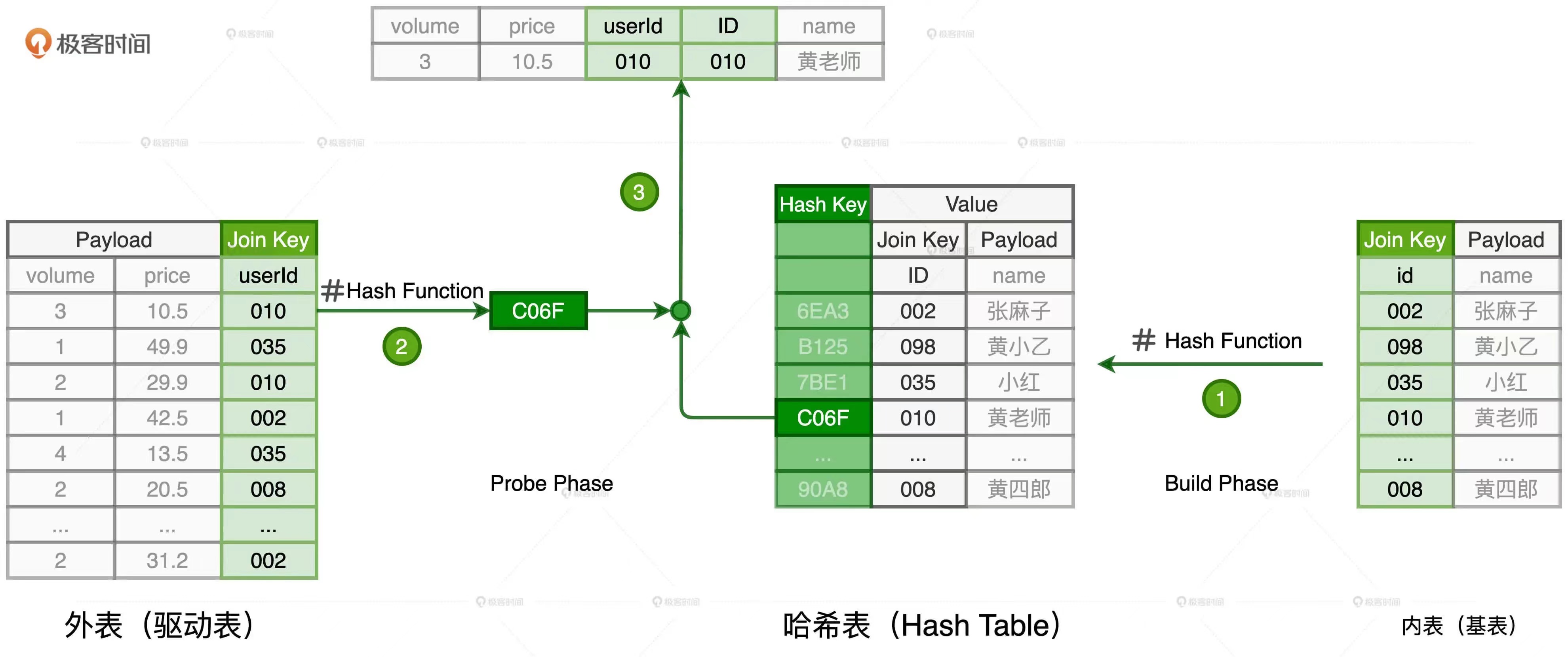
哈希-Hash Join(HJ):HJ的设计初衷:借助Hash Map,把内表扫描的时间复杂度降低至O(1)。具体做法:基于内表,根据给定的Hash函数构建哈希表。Hash表中的Key是Join Key应用哈希函数只有的哈希值。然后基于外表中的每一条数据,先使用同样的哈希函数以动态的方式计算Join Key的哈希值,用计算得到的哈希值去查询创建的哈希表。如果查询失败,说明外表中的这条记录与内表中的记录不存在关联关系;如果查询成功,就把两边的记录进行拼接输出。HJ算法的时间复杂度O(M)。
2、Spark中的Join策略-JoinSelection
在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据以下几种条件来选择最终的 Join 策略(join strategies):
- Join hints 策略
- Join 表的大小
- Join 是否等值
- 以及参与 Join 的 key 是否可以排序等
当前 Spark(Apache Spark 3.0)一共支持五种 Join 策略:
2.1 Broadcast Hash Join (BHJ)
基本原理(过程):
- 将小表从各Executor端Collect到Driver端;
- Driver端调用sparkContext.broadcast将表数据广播到计算的executor端;
- 在Executor端将广播的表加载到内存中,大表数据和内存中的Hash小表进行Join。
使用条件与特点:
- 仅支持等值连接,join key不需要排序。
- 支持除了全外连接(full outer joins)之外的所有join类型。
- Broadcast Hash Join相比其他的JOIN机制而言,效率更高。但是,Broadcast Hash Join属于网络密集型的操作(数据冗余传输),除此之外,需要在Driver端缓存数据,所以当小表的数据量较大时,会出现OOM的情况。
- 被广播的小表的数据量要小于spark.sql.autoBroadcastJoinThreshold值,默认是10MB(10485760)。
2.2 Shuffle Hash Join(SHJ)
基本原理(过程):
- 对大表和小表的Join Key使用相同的分区算法和分区数进行分区(Shuffle),保证相同Join Key在同一个分区,方便分区内进行Join;
- 将小表加载到内部才能构建Hash Map,本地进行Hash Join。
使用条件与特点:
- 仅支持等值连接,join key不需要排序。
- 支持除了全外连接(full outer joins)之外的所有join类型。
- 需要对小表构建Hash map,属于内存密集型的操作,如果构建Hash表的一侧数据比较大,可能会造成OOM。
- 参数设置:将参数spark.sql.join.prefersortmergeJoin (default true)置为false。
- 大表必须是小表的三倍以上。
2.3 Shuffle Sort Merge Join (SMJ)
基本原理(过程):
- 两张大表根据Join key进行Shuffle重分区;
- 分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接,不需要将一个表加载到内存中;
- 从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。
使用条件与特点:
- 仅支持等值连接。
- 支持所有join类型。
- Join Keys是排序的。
- 参数设置:参数spark.sql.join.prefersortmergeJoin (默认true)设定为true。
- 对表的大小没有限制:前两种策略都对小表有大小限制,而这种策略是不限制大小的;
2.4 Cartesian Product Join (CPJ)
基本原理(过程):
- 如果 Spark 中两张参与 Join 的表没指定join key(ON 条件)那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张行数的乘积。
使用条件与特点:
- 仅支持内连接。
- 支持等值和不等值连接。
- 开启参数spark.sql.crossJoin.enabled=true。
2.5 Broadcast Nested Loop Join (BNLJ)
基本原理(过程):
- 与Broadcast Hash Join类似,先对小表进行广播,但是不对广播后的小表建立hash表,而是for循环遍历广播表。
使用条件与特点:
- 支持等值和非等值连接。
- 支持所有Join类型。
- 支持所有的JOIN类型,主要优化点如下:
- 当右外连接时要广播左表。
- 当左外连接时要广播右表。
- 当内连接时,要广播左右两张表。
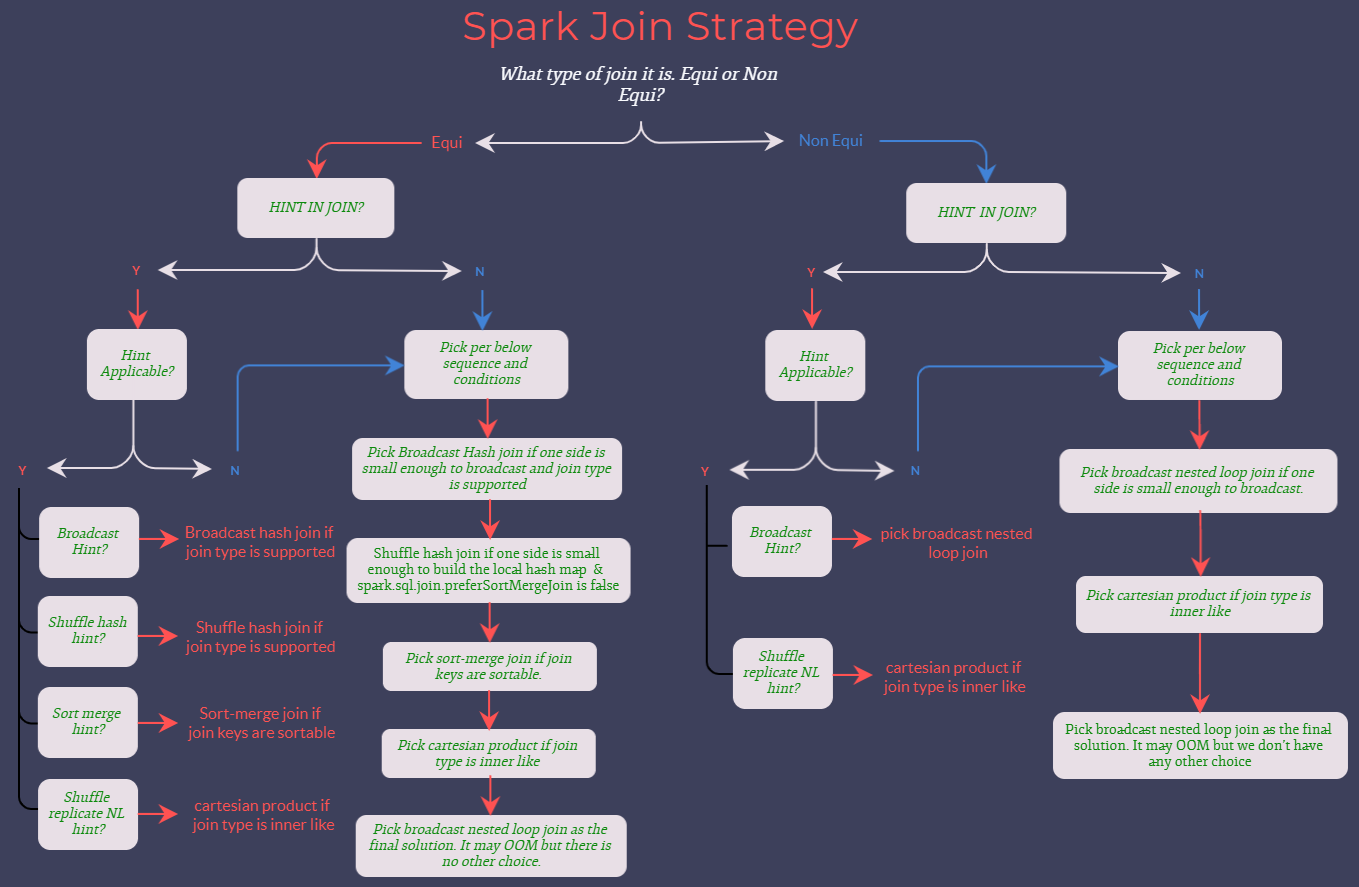
SparkStrategies.scala文件给出了各种Join方式的介绍:
/**
* Select the proper physical plan for join based on join strategy hints, the availability of
* equi-join keys and the sizes of joining relations. Below are the existing join strategies,
* their characteristics and their limitations.
*
* - Broadcast hash join (BHJ):
* Only supported for equi-joins, while the join keys do not need to be sortable.
* Supported for all join types except full outer joins.
* BHJ usually performs faster than the other join algorithms when the broadcast side is
* small. However, broadcasting tables is a network-intensive operation and it could cause
* OOM or perform badly in some cases, especially when the build/broadcast side is big.
*
* - Shuffle hash join:
* Only supported for equi-joins, while the join keys do not need to be sortable.
* Supported for all join types.
* Building hash map from table is a memory-intensive operation and it could cause OOM
* when the build side is big.
*
* - Shuffle sort merge join (SMJ):
* Only supported for equi-joins and the join keys have to be sortable.
* Supported for all join types.
*
* - Broadcast nested loop join (BNLJ):
* Supports both equi-joins and non-equi-joins.
* Supports all the join types, but the implementation is optimized for:
* 1) broadcasting the left side in a right outer join;
* 2) broadcasting the right side in a left outer, left semi, left anti or existence join;
* 3) broadcasting either side in an inner-like join.
* For other cases, we need to scan the data multiple times, which can be rather slow.
*
* - Shuffle-and-replicate nested loop join (a.k.a. cartesian product join):
* Supports both equi-joins and non-equi-joins.
* Supports only inner like joins.
*/
对于等值Join:
// If it is an equi-join, we first look at the join hints w.r.t. the following order:
// 1. broadcast hint: pick broadcast hash join if the join type is supported. If both sides
// have the broadcast hints, choose the smaller side (based on stats) to broadcast.
// 2. sort merge hint: pick sort merge join if join keys are sortable.
// 3. shuffle hash hint: We pick shuffle hash join if the join type is supported. If both
// sides have the shuffle hash hints, choose the smaller side (based on stats) as the
// build side.
// 4. shuffle replicate NL hint: pick cartesian product if join type is inner like.
//
// If there is no hint or the hints are not applicable, we follow these rules one by one:
// 1. Pick broadcast hash join if one side is small enough to broadcast, and the join type
// is supported. If both sides are small, choose the smaller side (based on stats)
// to broadcast.
// 2. Pick shuffle hash join if one side is small enough to build local hash map, and is
// much smaller than the other side, and `spark.sql.join.preferSortMergeJoin` is false.
// 3. Pick sort merge join if the join keys are sortable.
// 4. Pick cartesian product if join type is inner like.
// 5. Pick broadcast nested loop join as the final solution. It may OOM but we don't have
// other choice.
对于非等值Join:
// If it is not an equi-join, we first look at the join hints w.r.t. the following order:
// 1. broadcast hint: pick broadcast nested loop join. If both sides have the broadcast
// hints, choose the smaller side (based on stats) to broadcast for inner and full joins,
// choose the left side for right join, and choose right side for left join.
// 2. shuffle replicate NL hint: pick cartesian product if join type is inner like.
//
// If there is no hint or the hints are not applicable, we follow these rules one by one:
// 1. Pick broadcast nested loop join if one side is small enough to broadcast. If only left
// side is broadcast-able and it's left join, or only right side is broadcast-able and
// it's right join, we skip this rule. If both sides are small, broadcasts the smaller
// side for inner and full joins, broadcasts the left side for right join, and broadcasts
// right side for left join.
// 2. Pick cartesian product if join type is inner like.
// 3. Pick broadcast nested loop join as the final solution. It may OOM but we don't have
// other choice. It broadcasts the smaller side for inner and full joins, broadcasts the
// left side for right join, and broadcasts right side for left join.
相关阅读: