Spark——消费Kafka数据保存Offset到Redis
主要内容:
- Scala实现SparkStreaming消费Kafka数据保存Offset到Redis,实现自主维护Offset。
- 分析部分源码
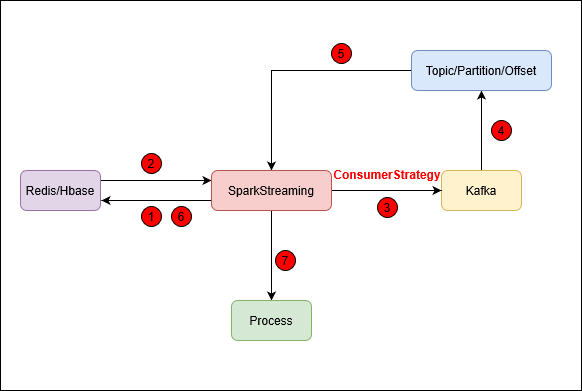
SparkStreaming自主维护Offset的流程
-
SparkStreaming启动时,先请求Redis或Hbase;
-
Redis或Hbase返回请求结果,将结果(Topic、Partition、Offset的组合)封装成
collection.Map[TopicPartition, Long]返回给SparkStreaming; -
SparkStreaming采用createDirectStream方式连接Kafka,并根据请求Redis或Hbase的结果确定ConsumerStrategy策略,而ConsumerStrategy策略由Subscribe决定。具体说来,若
collection.Map[TopicPartition, Long]对象为空或不存在时,则不指定offset消费kafka;若collection.Map[TopicPartition, Long]对象不为空,则指定offset消费kafka。下面对部分源码进行解释:createDirectStream函数需要三个参数:
ssc:SparkStreaming上下文locationStrategy:源码中建议传入:LocationStrategies.PreferConsistentconsumerStrategy:源码中建议传入:ConsumerStrategies.Subscribe
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]] = {
val ppc = new DefaultPerPartitionConfig(ssc.sparkContext.getConf)
createDirectStream[K, V](ssc, locationStrategy, consumerStrategy, ppc)
}
Subscribe函数可传入两个或三个参数:
topics:Kafka对应topickafkaParams:Kafka相关配置offsets:可传可不传,若传该参数,表示指定Offset消费Kafka
def Subscribe[K, V](
topics: Iterable[jl.String],
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long]): ConsumerStrategy[K, V] = {
new Subscribe[K, V](
new ju.ArrayList(topics.asJavaCollection),
new ju.HashMap[String, Object](kafkaParams.asJava),
new ju.HashMap[TopicPartition, jl.Long](offsets.mapValues(l => new jl.Long(l)).asJava))
}
- SparkStreaming消费Kafka得到
InputDStream[ConsumerRecord[K, V]]对象,其中ConsumerRecord对象:Topic、Partition、Offset等信息:
/**
* Creates a record to be received from a specified topic and partition
*
* @param topic The topic this record is received from
* @param partition The partition of the topic this record is received from
* @param offset The offset of this record in the corresponding Kafka partition
* @param timestamp The timestamp of the record.
* @param timestampType The timestamp type
* @param checksum The checksum (CRC32) of the full record
* @param serializedKeySize The length of the serialized key
* @param serializedValueSize The length of the serialized value
* @param key The key of the record, if one exists (null is allowed)
* @param value The record contents
* @param headers The headers of the record.
*/
public ConsumerRecord(String topic,
int partition,
long offset,
long timestamp,
TimestampType timestampType,
Long checksum,
int serializedKeySize,
int serializedValueSize,
K key,
V value,
Headers headers) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null");
this.topic = topic;
this.partition = partition;
this.offset = offset;
this.timestamp = timestamp;
this.timestampType = timestampType;
this.checksum = checksum;
this.serializedKeySize = serializedKeySize;
this.serializedValueSize = serializedValueSize;
this.key = key;
this.value = value;
this.headers = headers;
}
-
将上述信息返回给SparkStreaming;
-
SparkStreaming将其按一定方式处理后,存入Redis或Hbase;
-
SparkStreaming对消费到的Message作进一步的处理逻辑。
Redis数据结构设计
数据结构选择HashTable:
| Key | Filed | Value |
|---|---|---|
| groupid:topic | topic:partition | offset |
代码实现
Redis连接:org.ourhome.utils.RedisUtils
package org.ourhome.utils
import org.ourhome.cons.Constants
import redis.clients.jedis.Jedis
/**
* @Author Do
* @Date 2020/4/17 22:32
*/
class RedisUtils extends Serializable {
def getJedisConn: Jedis = {
new Jedis(Constants.HOST, Constants.PORT, Constants.TIMEOUT)
}
}
常量:org.ourhome.cons.Constants
package org.ourhome.cons
import org.apache.kafka.common.serialization.StringDeserializer
/**
* @Author Do
* @Date 2020/4/17 22:36
*/
object Constants {
val KAFKA_TOPIC: String = "kafka_producer_test"
private val KAFKA_GROUP_ID: String = "kafka_consumer"
val KAFKA_PARAMS = Map[String, Object](
"bootstrap.servers" -> "brokerList",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> KAFKA_GROUP_ID,
"auto.offset.reset" -> "latest", //earliest latest
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val HOST: String = "host"
val PORT: Int = 6379
val TIMEOUT: Int = 30000
val REDIS_KEY: String = KAFKA_GROUP_ID + ":" + KAFKA_TOPIC
}
主程序:org.ourhome.kafkatest.SaveOffsetToRedis
package org.ourhome.kafkatest
import java.util
import scala.collection.JavaConversions._
import org.apache.kafka.clients.consumer.{ConsumerRecord, OffsetAndMetadata, OffsetCommitCallback}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
import org.ourhome.utils.RedisUtils
import org.ourhome.cons.Constants
import scala.collection.mutable
/**
* @Author Do
* @Date 2020/4/17 22:27
*/
object SaveOffsetToRedis {
def main(args: Array[String]): Unit = {
// 创建spark运行环境
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("Spark Streaming Kafka")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val context: SparkContext = sparkSession.sparkContext
context.setLogLevel("WARN")
val streamingContext: StreamingContext = new StreamingContext(context, Seconds(1))
System.setProperty("hadoop.home.dir", "C:\\winutils") // 本地启动,解决hadoop报错问题,下载后添加环境变量
val partitionToLong: mutable.HashMap[TopicPartition, Long] = new mutable.HashMap[TopicPartition, Long]()
val conn: Jedis = new RedisUtils().getJedisConn
/**
* ConsumerStrategies.Subscribe参数:
* topics: ju.Collection[jl.String],
* kafkaParams: ju.Map[String, Object],
* offsets: ju.Map[TopicPartition, jl.Long] 有此参数,表示指定offset读kafka
*
* 消费策略:1.不指定offset 2.指定offset
* 启动时根据请求redis的结果,确定consumerStrategy消费策略:
* 若启动时,redis中键不存在,则不指定offset消费kafka
* 若启动时,redis中键存在:
* 若partitionToLong为空,即无topic、partition、offset,则不指定offset消费kafka
* 若partitionToLong不为空,指定offset消费kafka
*/
val consumerStrategy: ConsumerStrategy[String, String] = if (!conn.exists(Constants.REDIS_KEY)) {
printf("%s不存在,客户端会自动创建!", Constants.REDIS_KEY)
ConsumerStrategies.Subscribe[String, String](Array(Constants.KAFKA_TOPIC), Constants.KAFKA_PARAMS)
} else {
val redisResult: util.Map[String, String] = conn.hgetAll(Constants.REDIS_KEY)
redisResult.keySet().foreach(eachFiled => {
val strings: Array[String] = eachFiled.split(":")
println("strings:")
strings.foreach(i => println(i))
val topicPartition: TopicPartition = new TopicPartition(strings(0), strings(1).toInt)
val offsetValue: String = redisResult(eachFiled)
// 将每个partition中的offset保存在map中,作为subscribe参数
partitionToLong.put(topicPartition, offsetValue.toLong)
})
if (partitionToLong.nonEmpty) {
ConsumerStrategies.Subscribe[String, String](
Array(Constants.KAFKA_TOPIC),
Constants.KAFKA_PARAMS,
partitionToLong
)
} else {
ConsumerStrategies.Subscribe[String, String](Array(Constants.KAFKA_TOPIC), Constants.KAFKA_PARAMS)
}
}
conn.close()
/** KafkaUtils.createDirectStream参数:
* ssc: StreamingContext,
* locationStrategy: LocationStrategy,
* consumerStrategy: ConsumerStrategy[K, V]
*/
// 每次从kafka获取到的批数据
val dataStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
consumerStrategy
)
// 对数据做处理 foreachRDD——foreachPartition——foreach(record)
dataStream.foreachRDD(rdd => {
rdd.foreachPartition(partition => {
val conn: Jedis = new RedisUtils().getJedisConn
partition.foreach(record => {
println(record.value())
})
conn.close()
})
/**
* 返回一个批次数据中OffsetRange对象的信息
* OffsetRange(topic: 'kafka_producer_test', partition: 1, range: [152 -> 156])
* OffsetRange(topic: 'kafka_producer_test', partition: 2, range: [2589 -> 2592])
* OffsetRange(topic: 'kafka_producer_test', partition: 0, range: [2589 -> 2592])
*/
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 自动将offset保存到kafka
// dataStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
// 或
// dataStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges, new OffsetCommitCallback() {
// override def onComplete(offsets: java.util.Map[TopicPartition, OffsetAndMetadata], exception: Exception): Unit = {
// if (null != exception) {
// println("error")
// } else {
// println("success")
// }
// }
// })
offsetRanges.foreach(eachRange => {
val topic: String = eachRange.topic
val fromOffset: Long = eachRange.fromOffset
val endOffset: Long = eachRange.untilOffset
val partition: Int = eachRange.partition
conn.hset(Constants.REDIS_KEY, topic + ":" + partition, (endOffset + 1).toString)
})
})
streamingContext.start()
streamingContext.awaitTermination()
}
}